I spent some time to break itemcolorstrings.dat into its components to understand it and to create the current color number mod. With this topic I want to share my knowledge so that nobody has to do this again.
![]() This topic is very technical. Knowledge about binary and hexadecimal data is required to understand everything
This topic is very technical. Knowledge about binary and hexadecimal data is required to understand everything
Always keep a backup when modifying files. The worst thing that can happen is a game crash on startup.
Feel free to ask questions if anything is unclear ![]()
What you need if you want to try it yourself
- A Hex Editor for viewing and editing. I used a freeware editor called HxD to make the changes: Downloads | mh-nexus . It is available in many languages.
- Any version of itemcolorstrings.dat from Boundless
![]() Do not try editing with a normal text editor. It will likely break the file when saving.
Do not try editing with a normal text editor. It will likely break the file when saving.
General info
- Positions in the file are given as hexadecimal positions with the decimal representation in brackets like: A10 (2576)
- Pointers (references in the file) are in little endian. This means that a pointer to position 6789ABCD is stored as CD AB 89 67
- Strings so far are encoded with 1 byte per character in ISO_8859_1 (Latin-1) format.
- Quoted words like “Language definition” reference to other parts of the file structure.
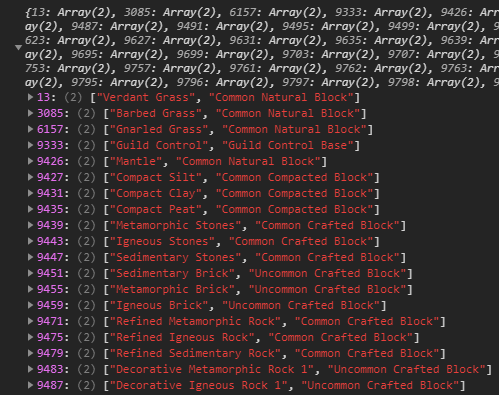
Data shown is on the example of the first English names for item descriptions
Time to dive into the data!
Overall file structure
1 Header
2 Language definition
3 Language section
4 Name section
5 Combination offset data
6 Word combination data
7 String offset data
8 String data
4 Name section
...
3 Language section
...
1. Header
The file starts with some kind of information which I did not decode. It was not required so far to change anything of this
2. Language definition

This is where the interesting things start with the language definition.
This is currently 58 Bytes long
Start position: DA2 (3490). If it changes in the future it is easily identifiable by the words: english french german italian spanish
The structure here (5 times):
- 1 Byte: length of the following string
- x Bytes: String data of above length in ISO_8859_1 (Latin-1) format
- 4 Bytes: Pointer in file to language section. Example for english: DC 0D 00 00 is position 00000DDC (3548)
Ends after the spanish pointer. This is the position where the english pointer references to
3. Language section
![]()
This is a list of the 4 “Name section” for a language
There is 1 for every language at the position specified in the “Language definition”
This section is very small with 12 Bytes
The structure here:
- 4 Bytes: Pointer to color names
- 4 Bytes: Pointer to metal names
- 4 Bytes: Pointer to item names
Directly after starts the first “Name section” for item descriptions
4. Name section
![]()
This is the section which contains the pointers how the names are put together.
There are currently 4 of these per language. First starts directly after the “Language section”. The others at the pointers specified in the “Language section”
This section is very small with 12 Bytes
The structure here:
- 4 Bytes: Pointer to "Word combination data". Instructions how the words are put together
- 4 Bytes: Pointer to "String offset data". The length of each word is in here
- 4 Bytes: Pointer to "String data". All words without any separator
Directly after starts the “Combination offset data”. The length of each word combination
5. Combination offset data

This is a list of lengths for the “Word combination data”
There is 1 per “Name section”
This data varies in size depending on the combinations
The structure here:
- 1 Byte: bit length of values
- x Bytes: bit array with above bit length for each entry. Ends with start of "Word combination data"
How to decode:
09 00 06 14 48 B0 A0 01 84 09 16 32 ...
09 is the length of 9 bits
The following data needs to be translated to bits and split into above bit length (here: 9 bits) to interpret them as a number.
Showing the first hex values, their binary representation -> the split value = its decimal value
00 00000000
06 0000011 0 -> 0 00000000 = 0
14 000101 00 -> 00 0000011 = 3
48 01001 000 -> 000 000101 = 5
B0 1011 0000 -> 0000 01001 = 9
A0 101 00000 -> 00000 1011 = 11
01 00 000001 -> 000001 101 = 13
84 1 0000100 -> 0000100 00 = 16
09 00001001 -> 00001001 1 = 19
16 00010110
32 0011001 0 -> 0 00010110 = 22
6. Word combination data

This contains the information how names are created from the single words
There is 1 per “Name section”
This data varies in size depending on the “Combination offset data”
The structure here:
- x Bytes: 1st combination going from "Combination offset data" entry 1 up to entry 2. In the example 0 to 2 (3 Bytes)
- x Bytes: 2nd combination
...
- x Bytes: last combination going from last entry to end of data
How to decode:
The data needs to be translated to bits
The general structure:
- length indicator bits which is either 0, 01, 11. This represents 3, 6, 10 bits are following
- number with amount of bits of length indicator representing word amount
Then for each word:
- length indicator
- word position in list created with "String offset data"
06 49 04 06 C8 56 14 73 14 ...
Showing the first hex values split by the "Combination offset data" -> reorder due to little endian,
their binary representation and the interpretation reading the binary from right to left
06 49 04 -> 04 49 06, 00000100 01001001 00000110
0: 3 bits next
011: number 3 -> 3 words
0: 3 bits next
000: number 0 -> word 1 from word list: Rare
01: 6 bits next
010010: number 18 -> word 19 from word list: Crafted
0: 3 bits next
010: number 2 -> word 3 from word list: Block
= Rare Crafted Block
06 C8 -> C8 06, 11001000 00000110
0: 3 bits next
011: number 3 -> 3 words
0: 3 bits next
000: number 0 -> word 1 from word list: Rare
0: 3 bits next
100: number 4 -> word 5 from word list: Crafting
0: 3 bits next
110: number 6 -> word 7 from word list: Ingredient
= Rare Crafting Ingredient
56 14 73 14 -> 14 73 14 56, 00010100 01110011 00010100 01010110
0: 3 bits next
011: number 3 -> 3 words
01: 6 bits next
010001: number 17 -> word 18 from word list: Decorative
01: 6 bits next
001100: number 12 -> word 13 from word list: Beacon
11: 10 bits next
0001010001: number 81 -> word 82 from word list: Fitting
= Decorative Beacon Fitting
7. String offset data
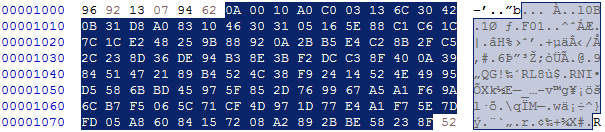
This is a list of lengths of the strings in “String data”
There is 1 per “Name section”
This data varies in size depending on the “String data”
The structure here:
- 1 Byte: bit length of values
- x Bytes: bit array with above bit length for each entry. Ends with start of "String data"
How to decode (Works same as "Combination offset data"):
0A 00 10 A0 C0 03 13 6C ...
0A is the length of 10 bits
The following data needs to be translated to bits and split into above bit length (here: 10 bits) to interpret them as a number.
Showing the first hex values, their binary representation -> the split value = its decimal value
00 00000000
10 000100 00 -> 00 00000000 = 0
A0 1010 0000 -> 0000 000100 = 4
C0 11 000000 -> 000000 1010 = 10
03 00000011 -> 00000011 11 = 15
13 00010011
6C 011011 00 -> 00 00010011 = 19
8. String data
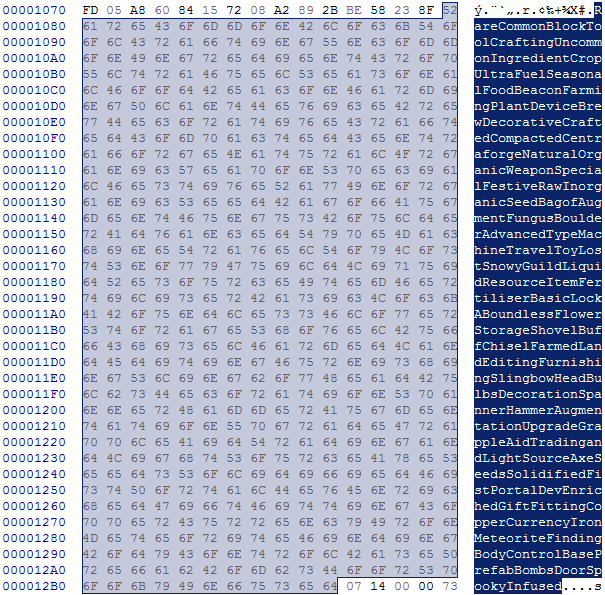
This is the text of all words without any separator
There is 1 per “Name section”
This data varies in size depending on the amount of words in it
The structure here:
- x Bytes: 1 byte per character in ISO_8859_1 (Latin-1) encoding until next "Name section" starts or file ends
How to decode:
Take the lengths from "String offset data" to get the length of each word
0, 4: Offset 0. 4 - 0 = 4 Length -> Rare
4, 10: Offset 4. 10 - 4 = 6 Length -> Common
10, 15: Offset 10. 15 - 10 = 5 Length -> Block
15, 19: Offset 15. 19 - 15 = 4 Length -> Tool
Enjoy creating great things with this knowledge ![]()

 but cool to see you figure it out! ]
but cool to see you figure it out! ]