We have a problem: Tana VII, Gyosha Ophin and Houchus I are unavailable for months for many players. It’s a huge trouble for me personaly because I live on Norkyna and Houchus is only single path to outer universe.
I am in oz…It’s been running pretty good…but it took a lot of phone calls to my internet company and changed my router replaced bad wiring…it worked almost…I still get connection issues on besi and on meteor hunts. I even got booted on a meteor. Oh game crashes at least twice if full day playing… so after I upgraded everything to be over the top issues are still there.its definitely not internet issues like I keep getting told by my screen…Lol… but the positive note it’s mainly when hunting I get my issues. The rest of the time it’s pretty good
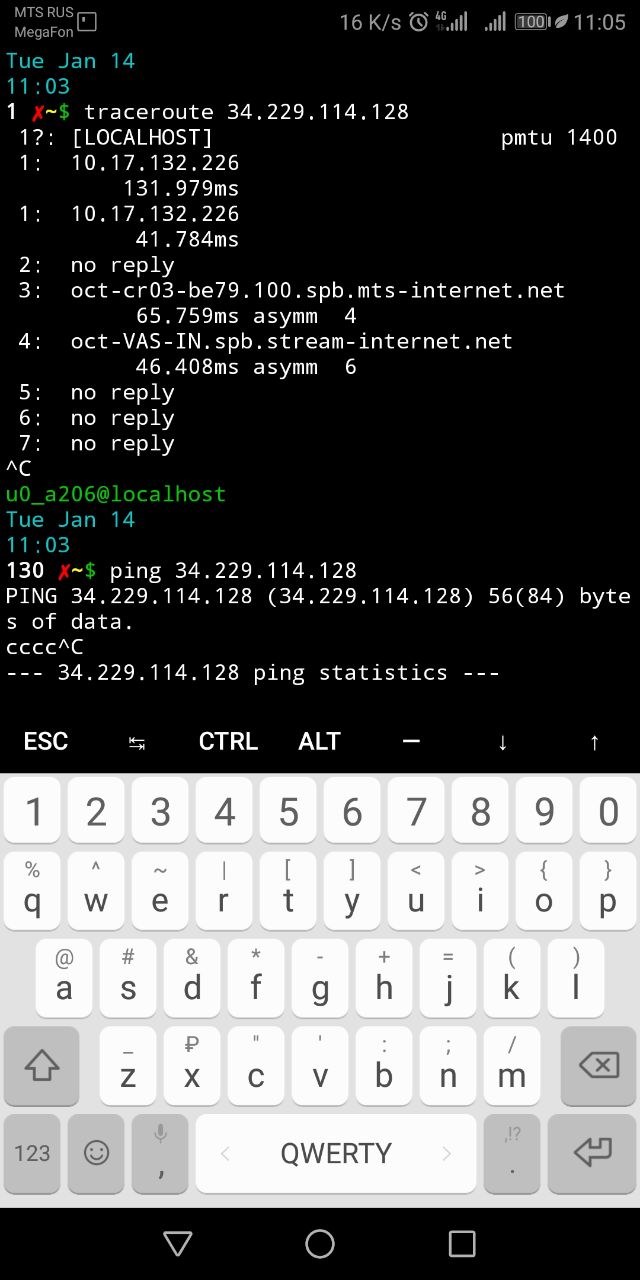
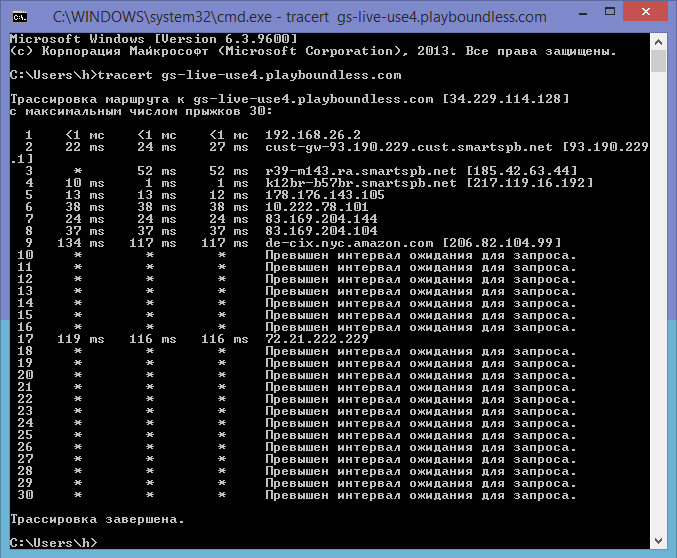
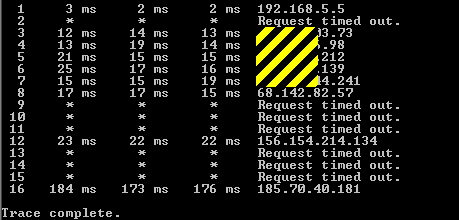
So how is USE4 troublesome? A 134 and 119 response is acceptable for game play. Unfortunately I can’t read the language but even then the * means usually that the router just doesn’t respond to tracert queries.
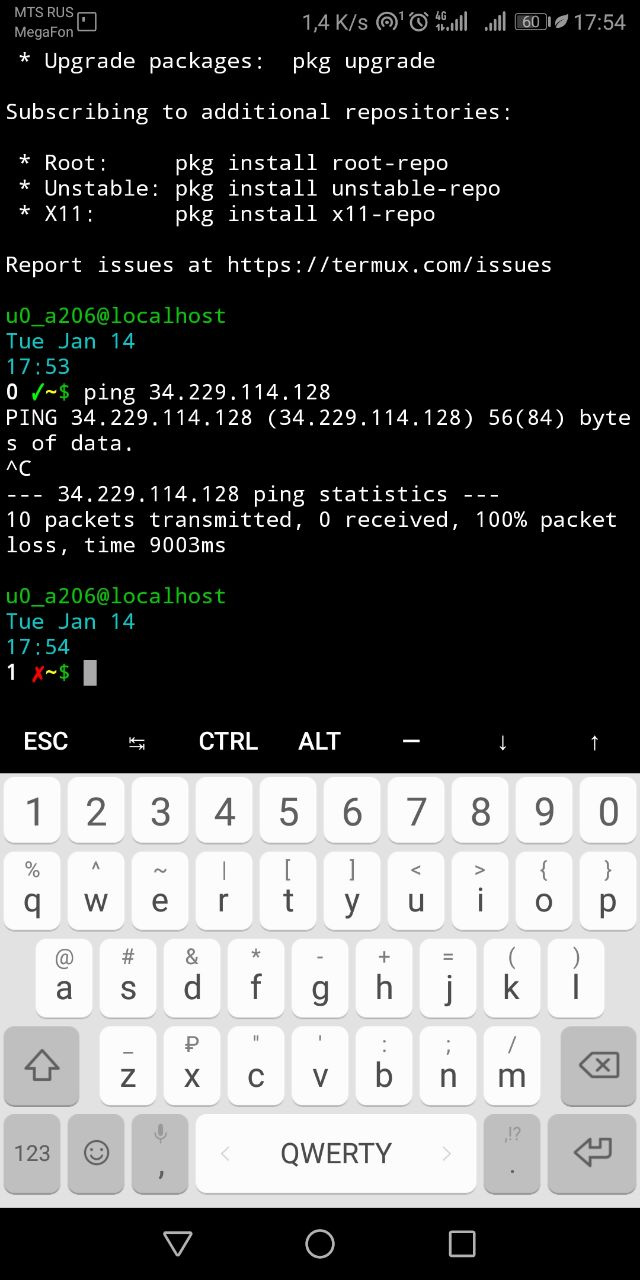
I don’t sure how to catch a problem by ping or trace because ping is done. But game still returns “Game server offline” or “Timed out connecting to server” for two month without any hope to change situation.
Other then in his case, that is likely not the case,
When you see * littered about every now and then, then yes, that is what it can mean, but when you see many in a row, and the trace route terminates with *, then that is much more likely a connection problem and not the machine refusing to respond to ICMP,
from hop 18 to hop 30 is all *, that is highly suggestive of a connection problem in most cases, especially when it is known that the end point should respond to ICMP as seen below
Yeah that sucks sometimes because you can’t always see the full route and where things are really going bad. It is definitely something between you and AWS because some of us aren’t seeing same problems. Sorry to hear.
it is possible to create a portal from kolhuroo to norkyna. it’s 20 blinksecs. Mind you that one is on euc4 which may be worse depending where you are… Not sure if that’s helpful for you or not :S
Those are different hops and aren’t responding to the ICMP request or it moved past the TTL. Those hops if going past TTL could mean a connection problem but again I wouldn’t say it was “suggestive” at all.
Being that we don’t see the final IP or name as being the Boundless server that is queried we don’t know if there is a problem point further down in the chain. Being that others are using the servers and not having the same response primarily means that it isn’t the end point that is the problem but the path to it.
I do wonder if they would consider standing up a different region in the USE4 area to see if that helps performance to some locations. I wonder if there is a way to test that…
Then I guess our experiences for tshooting in the field differ by quite an amount
I never stated that the end point was the problem, or anything about where the problem was, just the simple fact that in my experiences, many *s is typically alot more suggestive of connection problems rather then security configurations
Well until the person that posted the screenshot gives me a translation of the words at the end of each line I cannot know for certain. If the words read: Request timed out, then I would agree that there was a problem.
At the end of the day it is very common for some routers and hops to not respond back to ICMP. But, obviously without the missing details we might approach things differently. If the Ping was responding very high then I would be suspect more when looking at a trace route.
My point about “the end point being the issue” was directed at the original OP comments that USE4 was troublesome and that the best solution was to relocate it. For me, considering the servers sit on an AWS infrastructure and not a smaller ISP Data center, it would be very unlikely that the AWS hops are saturated. So that would be that the issue is still somewhere between point A and B. Something the Boundless Devs cannot fix. Moving to a new region or availability zone in AWS might improve performance if the route changes enough, but only a test would prove that for certain.